This seems to be an area with quite a few myths and conflicting views.
So what is the difference between a table variable and a local temporary table in SQL Server?
This seems to be an area with quite a few myths and conflicting views.
So what is the difference between a table variable and a local temporary table in SQL Server?
Contents

Caveat
This answer discusses "classic" table variables introduced in SQL Server 2000. SQL Server 2014 in memory OLTP introduces Memory-Optimized Table Types. Table variable instances of those are different in many respects to the ones discussed below! (more details).
Storage Location
No difference. Both are stored in tempdb.
I've seen it suggested that for table variables this is not always the case but this can be verified from the below
DECLARE @T TABLE(X INT)
INSERT INTO @T VALUES(1),(2)
SELECT sys.fn_PhysLocFormatter(%%physloc%%) AS [File:Page:Slot]
FROM @T
Example results (showing location in tempdb the 2 rows are stored)
File:Page:Slot
----------------
(1:148:0)
(1:148:1)
Logical Location
Table variables behave more as though they were part of the current database than #temp tables do. For table variables (since 2005) column collations if not specified explicitly will be that of the current database whereas for #temp tables it will use the default collation of tempdb (More details).
User-defined data types and XML collections must be in tempdb to use for #temp tables and table variables (Source). User-defined alias types must exist in tempdb for #temp tables, but table variables use the context database.
SQL Server 2012 introduces contained databases. the behavior of temporary tables in these differs (h/t Aaron)
In a contained database temporary table data is collated in the collation of the contained database.
- All metadata associated with temporary tables (for example, table and column names, indexes, and so on) will be in the catalog collation.
- Named constraints may not be used in temporary tables.
- Temporary tables may not refer to user-defined types, XML schema collections, or user-defined functions.
Visibility to different scopes
Table variables can only be accessed within the batch and scope in which they are declared. #temp tables are accessible within child batches (nested triggers, procedure, exec calls). #temp tables created at the outer scope (@@NESTLEVEL=0) can span batches too as they persist until the session ends. Neither type of object can be created in a child batch and accessed in the calling scope however as discussed next (global ##temp tables can be though).
Lifetime
Table variables are created implicitly when a batch containing a DECLARE @.. TABLE statement is executed (before any user code in that batch runs) and are dropped implicitly at the end.
Although the parser will not allow you to try and use the table variable before the DECLARE statement the implicit creation can be seen below.
IF (1 = 0)
BEGIN
DECLARE @T TABLE(X INT)
END
--Works fine
SELECT *
FROM @T
#temp tables are created explicitly when the TSQL CREATE TABLE statement is encountered and can be dropped explicitly with DROP TABLE or will be dropped implicitly when the batch ends (if created in a child batch with @@NESTLEVEL > 0) or when the session ends otherwise.
NB: Within stored routines both types of object can be cached rather than repeatedly creating and dropping new tables. There are restrictions on when this caching can occur however that are possible to violate for #temp tables but which the restrictions on table variables prevent anyway. The maintenance overhead for cached #temp tables is slightly greater than for table variables as illustrated here.
Object Metadata
This is essentially the same for both types of object. It is stored in the system base tables in tempdb. It is more straightforward to see for a #temp table however as OBJECT_ID('tempdb..#T') can be used to key into the system tables and the internally generated name is more closely correlated with the name defined in the CREATE TABLE statement. For table variables the object_id function does not work and the internal name is entirely system generated with no relationship to the variable name (the name is the hexadecimal form of the object id).
The below demonstrates the metadata is still there however by keying in on a (hopefully unique) column name. For tables without unique column names the object_id can be determined using DBCC PAGE as long as they are not empty.
/*Declare a table variable with some unusual options.*/
DECLARE @T TABLE
(
[dba.se] INT IDENTITY PRIMARY KEY NONCLUSTERED,
A INT CHECK (A > 0),
B INT DEFAULT 1,
InRowFiller char(1000) DEFAULT REPLICATE('A',1000),
OffRowFiller varchar(8000) DEFAULT REPLICATE('B',8000),
LOBFiller varchar(max) DEFAULT REPLICATE(cast('C' as varchar(max)),10000),
UNIQUE CLUSTERED (A,B)
WITH (FILLFACTOR = 80,
IGNORE_DUP_KEY = ON,
DATA_COMPRESSION = PAGE,
ALLOW_ROW_LOCKS=ON,
ALLOW_PAGE_LOCKS=ON)
)
INSERT INTO @T (A)
VALUES (1),(1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12),(13)
SELECT t.object_id,
t.name,
p.rows,
a.type_desc,
a.total_pages,
a.used_pages,
a.data_pages,
p.data_compression_desc
FROM tempdb.sys.partitions AS p
INNER JOIN tempdb.sys.system_internals_allocation_units AS a
ON p.hobt_id = a.container_id
INNER JOIN tempdb.sys.tables AS t
ON t.object_id = p.object_id
INNER JOIN tempdb.sys.columns AS c
ON c.object_id = p.object_id
WHERE c.name = 'dba.se'
Output
Duplicate key was ignored.
| object_id | name | rows | type_desc | total_pages | used_pages | data_pages | data_compression_desc |
|---|---|---|---|---|---|---|---|
| 574625090 | #22401542 | 13 | IN_ROW_DATA | 2 | 2 | 1 | PAGE |
| 574625090 | #22401542 | 13 | LOB_DATA | 24 | 19 | 0 | PAGE |
| 574625090 | #22401542 | 13 | ROW_OVERFLOW_DATA | 16 | 14 | 0 | PAGE |
| 574625090 | #22401542 | 13 | IN_ROW_DATA | 2 | 2 | 1 | NONE |
Object ids for temporary tables and table variables were positive before SQL Server 2012. From SQL Server 2012 onwards, object ids for temporary tables and table variables are always negative (high bit set).
Transactions
Operations on table variables are carried out as system transactions, independent of any outer user transaction, whereas the equivalent #temp table operations would be carried out as part of the user transaction itself. For this reason a ROLLBACK command will affect a #temp table but leave a table variable untouched.
DECLARE @T TABLE(X INT)
CREATE TABLE #T(X INT)
BEGIN TRAN
INSERT #T
OUTPUT INSERTED.X INTO @T
VALUES(1),(2),(3)
/*Both have 3 rows*/
SELECT * FROM #T
SELECT * FROM @T
ROLLBACK
/*Only table variable now has rows*/
SELECT * FROM #T
SELECT * FROM @T
DROP TABLE #T
Logging
Both generate log records to the tempdb transaction log. A common misconception is that this is not the case for table variables so a script demonstrating this is below, it declares a table variable, adds a couple of rows then updates them and deletes them.
Because the table variable is created and dropped implicitly at the start and the end of the batch it is necessary to use multiple batches in order to see the full logging.
USE tempdb;
/*
Don't run this on a busy server.
Ideally should be no concurrent activity at all
*/
CHECKPOINT;
GO
/*
The 2nd column is binary to allow easier correlation with log output shown later*/
DECLARE @T TABLE ([C71ACF0B-47E9-4CAD-9A1E-0C687A8F9CF3] INT, B BINARY(10))
INSERT INTO @T
VALUES (1, 0x41414141414141414141),
(2, 0x41414141414141414141)
UPDATE @T
SET B = 0x42424242424242424242
DELETE FROM @T
/*Put allocation_unit_id into CONTEXT_INFO to access in next batch*/
DECLARE @allocId BIGINT, @Context_Info VARBINARY(128)
SELECT @Context_Info = allocation_unit_id,
@allocId = a.allocation_unit_id
FROM sys.system_internals_allocation_units a
INNER JOIN sys.partitions p
ON p.hobt_id = a.container_id
INNER JOIN sys.columns c
ON c.object_id = p.object_id
WHERE ( c.name = 'C71ACF0B-47E9-4CAD-9A1E-0C687A8F9CF3' )
SET CONTEXT_INFO @Context_Info
/*Check log for records related to modifications of table variable itself*/
SELECT Operation,
Context,
AllocUnitName,
[RowLog Contents 0],
[Log Record Length]
FROM fn_dblog(NULL, NULL)
WHERE AllocUnitId = @allocId
GO
/*Check total log usage including updates against system tables*/
DECLARE @allocId BIGINT = CAST(CONTEXT_INFO() AS BINARY(8));
WITH T
AS (SELECT Operation,
Context,
CASE
WHEN AllocUnitId = @allocId THEN 'Table Variable'
WHEN AllocUnitName LIKE 'sys.%' THEN 'System Base Table'
ELSE AllocUnitName
END AS AllocUnitName,
[Log Record Length]
FROM fn_dblog(NULL, NULL) AS D)
SELECT Operation = CASE
WHEN GROUPING(Operation) = 1 THEN 'Total'
ELSE Operation
END,
Context,
AllocUnitName,
[Size in Bytes] = COALESCE(SUM([Log Record Length]), 0),
Cnt = COUNT(*)
FROM T
GROUP BY GROUPING SETS( ( Operation, Context, AllocUnitName ), ( ) )
ORDER BY GROUPING(Operation),
AllocUnitName
Returns
Detailed view
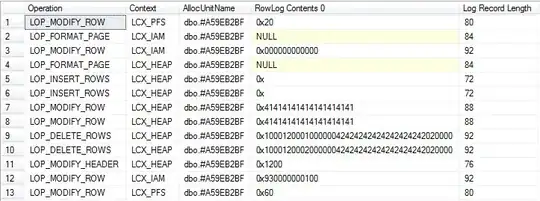
Summary View (includes logging for implicit drop and system base tables)
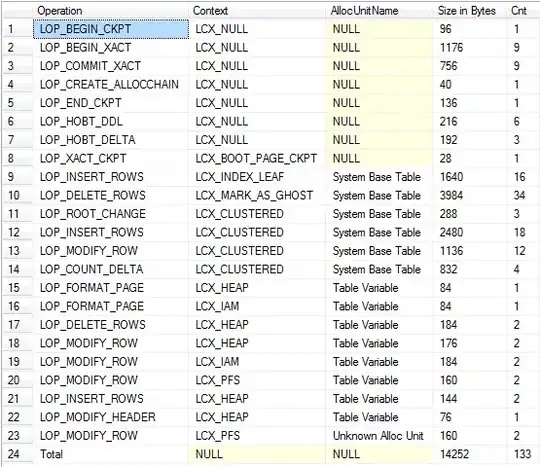
As far as I've been able to discern operations on both generate roughly equal amounts of logging.
Whilst the quantity of logging is very similar one important difference is that log records related to #temp tables can not be cleared out until any containing user transaction finishes so a long running transaction that at some point writes to #temp tables will prevent log truncation in tempdb whereas the autonomous transactions spawned for table variables do not.
Table variables do not support TRUNCATE so can be at a logging disadvantage when the requirement is to remove all rows from a table (though for very small tables DELETE can work out better anyway)
Cardinality
Many of the execution plans involving table variables will show a single row estimated as the output from them. Inspecting the table variable properties shows that SQL Server believes the table variable has zero rows (Why it estimates one row will be emitted from a zero row table is explained by Paul White here).
However, the results shown in the previous section do show an accurate rows count in sys.partitions. The issue is that on most occasions the statements referencing table variables are compiled while the table is empty. If the statement is (re)compiled after the table variable is populated, the current row count will be used for the table cardinality instead (this might happen due to an explicit recompile or perhaps because the statement also references another object that causes a deferred compile or a recompile.)
DECLARE @T TABLE(I INT);
INSERT INTO @T VALUES(1),(2),(3),(4),(5)
CREATE TABLE #T(I INT)
/*Reference to #T means this statement is subject to deferred compile*/
SELECT * FROM @T WHERE NOT EXISTS(SELECT * FROM #T)
DROP TABLE #T
Plan shows accurate estimated row count following deferred compile.
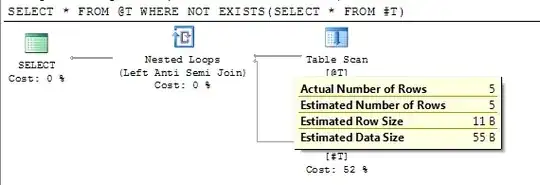
In SQL Server 2012 SP2, trace flag 2453 is introduced. More details are under "Relational Engine" here.
When this trace flag is enabled it can cause automatic recompiles to take account of changed cardinality as discussed further very shortly.
NB: On Azure in compatibility level 150 compilation of the statement is now deferred until first execution. This means that it will no longer be subject to the zero row estimate problem.
No column statistics
Having a more accurate table cardinality doesn't mean the estimated row count will be any more accurate however (unless doing an operation on all rows in the table). SQL Server does not maintain column statistics for table variables at all so will fall back on guesses based upon the comparison predicate (e.g. that 10% of the table will be returned for an = against a non unique column or 30% for a > comparison). In contrast column statistics are maintained for #temp tables.
SQL Server maintains a count of the number of modifications made to each column. If the number of modifications since the plan was compiled exceeds the recompilation threshold (RT) then the plan will be recompiled and statistics updated. The RT depends on table type and size.
From Plan Caching in SQL Server 2008
RT is calculated as follows. (n refers to a table's cardinality when a query plan is compiled.)
Permanent table
- If n <= 500, RT = 500.
- If n > 500, RT = 500 + 0.20 * n.
Temporary table
- If n < 6, RT = 6.
- If 6 <= n <= 500, RT = 500.
- If n > 500, RT = 500 + 0.20 * n.
Table variable- RT does not exist. Therefore, recompilations do not happen because of changes in cardinalities of table variables. (But see note about TF 2453 below)
the KEEP PLAN hint can be used to set the RT for #temp tables the same as for permanent tables.
The net effect of all this is that often the execution plans generated for #temp tables are orders of magnitudes better than for table variables when many rows are involved as SQL Server has better information to work with.
NB1: Table variables do not have statistics but can still incur a "Statistics Changed" recompile event under trace flag 2453 (does not apply for "trivial" plans) This appears to occur under the same recompile thresholds as shown for temp tables above with an additional one that if N=0 -> RT = 1. i.e. all statements compiled when the table variable is empty will end up getting a recompile and corrected TableCardinality the first time they are executed when non empty. The compile time table cardinality is stored in the plan and if the statement is executed again with the same cardinality (either due to flow of control statements or reuse of a cached plan) no recompile occurs.
NB2: For cached temporary tables in stored procedures the recompilation story is much more complicated than described above. See Temporary Tables in Stored Procedures for all the details.
Recompiles
As well as the modification based recompiles described above #temp tables can also be associated with additional compiles simply because they allow operations that are prohibited for table variables that trigger a compile (e.g. DDL changes CREATE INDEX, ALTER TABLE)
Locking
It has been stated that table variables do not participate in locking. This is not the case. Running the below outputs to the SSMS messages tab the details of locks taken and released for an insert statement.
DECLARE @tv_target TABLE (c11 int, c22 char(100))
DBCC TRACEON(1200,-1,3604)
INSERT INTO @tv_target (c11, c22)
VALUES (1, REPLICATE('A',100)), (2, REPLICATE('A',100))
DBCC TRACEOFF(1200,-1,3604)
For queries that SELECT from table variables Paul White points out in the comments that these automatically come with an implicit NOLOCK hint. This is shown below
DECLARE @T TABLE(X INT);
SELECT X
FROM @T
OPTION (RECOMPILE, QUERYTRACEON 3604, QUERYTRACEON 8607)
*** Output Tree: (trivial plan) ***
PhyOp_TableScan TBL: @T Bmk ( Bmk1000) IsRow: COL: IsBaseRow1002 Hints( NOLOCK )
The impact of this on locking might be quite minor however.
SET NOCOUNT ON;
CREATE TABLE #T( [ID] [int] IDENTITY NOT NULL,
[Filler] [char](8000) NULL,
PRIMARY KEY CLUSTERED ([ID] DESC))
DECLARE @T TABLE ( [ID] [int] IDENTITY NOT NULL,
[Filler] [char](8000) NULL,
PRIMARY KEY CLUSTERED ([ID] DESC))
DECLARE @I INT = 0
WHILE (@I < 10000)
BEGIN
INSERT INTO #T DEFAULT VALUES
INSERT INTO @T DEFAULT VALUES
SET @I += 1
END
/*Run once so compilation output doesn't appear in lock output*/
EXEC('SELECT *, sys.fn_PhysLocFormatter(%%physloc%%) FROM #T')
DBCC TRACEON(1200,3604,-1)
SELECT *, sys.fn_PhysLocFormatter(%%physloc%%)
FROM @T
PRINT '--*--'
EXEC('SELECT *, sys.fn_PhysLocFormatter(%%physloc%%) FROM #T')
DBCC TRACEOFF(1200,3604,-1)
DROP TABLE #T
Neither of these return results in index key order indicating that SQL Server used an allocation ordered scan for both.
I ran the above script twice and the results for the second run are below
Process 58 acquiring Sch-S lock on OBJECT: 2:-1325894110:0 (class bit0 ref1) result: OK
--*--
Process 58 acquiring IS lock on OBJECT: 2:-1293893996:0 (class bit0 ref1) result: OK
Process 58 acquiring S lock on OBJECT: 2:-1293893996:0 (class bit0 ref1) result: OK
Process 58 releasing lock on OBJECT: 2:-1293893996:0
The locking output for the table variable is indeed extremely minimal as SQL Server just acquires a schema stability lock on the object. But for a #temp table it is nearly as light in that it takes out an object level S lock. A NOLOCK hint or READ UNCOMMITTED isolation level can of course be specified explicitly when working with #temp tables as well.
Similarly to the issue with logging a surrounding user transaction can mean that the locks are held longer for #temp tables. With the script below
--BEGIN TRAN;
CREATE TABLE #T (X INT,Y CHAR(4000) NULL);
INSERT INTO #T (X) VALUES(1)
SELECT CASE resource_type
WHEN 'OBJECT' THEN OBJECT_NAME(resource_associated_entity_id, 2)
WHEN 'ALLOCATION_UNIT' THEN (SELECT OBJECT_NAME(object_id, 2)
FROM tempdb.sys.allocation_units a
JOIN tempdb.sys.partitions p ON a.container_id = p.hobt_id
WHERE a.allocation_unit_id = resource_associated_entity_id)
WHEN 'DATABASE' THEN DB_NAME(resource_database_id)
ELSE (SELECT OBJECT_NAME(object_id, 2)
FROM tempdb.sys.partitions
WHERE partition_id = resource_associated_entity_id)
END AS object_name,
*
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID
DROP TABLE #T
-- ROLLBACK
when run outside of an explicit user transaction for both cases the only lock returned when checking sys.dm_tran_locks is a shared lock on the DATABASE.
On uncommenting the BEGIN TRAN ... ROLLBACK 26 rows are returned showing that locks are held both on the object itself and on system table rows to allow for rollback and prevent other transactions from reading uncommitted data. The equivalent table variable operation is not subject to rollback with the user transaction and has no need to hold these locks for us to check in the next statement but tracing locks acquired and released in Profiler or using trace flag 1200 shows plenty of locking events do still occur.
Indexes
For versions prior to SQL Server 2014 indexes can only be created implicitly on table variables as a side effect of adding a unique constraint or primary key. This does of course mean that only unique indexes are supported. A non unique non clustered index on a table with a unique clustered index can be simulated however by simply declaring it UNIQUE NONCLUSTERED and adding the CI key to the end of the desired NCI key (SQL Server would do this behind the scenes anyway even if a non unique NCI could be specified)
As demonstrated earlier various index_options can be specified in the constraint declaration including DATA_COMPRESSION, IGNORE_DUP_KEY, and FILLFACTOR (though there is no point in setting that one as it would only make any difference on index rebuild and you can't rebuild indexes on table variables!)
Additionally table variables do not support INCLUDEd columns, filtered indexes (until 2016) or partitioning, #temp tables do (the partition scheme must be created in tempdb).
Indexes in SQL Server 2014
Non unique indexes can be declared inline in the table variable definition in SQL Server 2014. Example syntax for this is below.
DECLARE @T TABLE (
C1 INT INDEX IX1 CLUSTERED, /*Single column indexes can be declared next to the column*/
C2 INT INDEX IX2 NONCLUSTERED,
INDEX IX3 NONCLUSTERED(C1,C2) /*Example composite index*/
);
Indexes in SQL Server 2016
From CTP 3.1 it is now possible to declare filtered indexes for table variables. By RTM it may be the case that included columns are also allowed albeit they will likely not make it into SQL16 due to resource constraints
DECLARE @T TABLE
(
c1 INT NULL INDEX ix UNIQUE WHERE c1 IS NOT NULL /*Unique ignoring nulls*/
)
Parallelism
Queries that insert into (or otherwise modify) table variables cannot have a parallel plan, #temp tables are not restricted in this manner.
There is an apparent workaround in that rewriting as follows does allow the SELECT part to take place in parallel but that ends up using a hidden temporary table (behind the scenes)
INSERT INTO @DATA ( ... )
EXEC('SELECT .. FROM ...')
There is no such limitation in queries that select from table variables as illustrated in my answer here
Other Functional Differences
#temp_tables cannot be used inside a function. Table variables can be used inside scalar or multi-statement table UDFs.SELECT-ed INTO, ALTER-ed, TRUNCATEd or be the target of DBCC commands such as DBCC CHECKIDENT or of SET IDENTITY INSERT and do not support table hints such as WITH (FORCESCAN)CHECK constraints on table variables are not considered by the optimizer for simplification, implied predicates or contradiction detection.PAGELATCH_EX waits. (Example)Memory Only?
As stated at the beginning both get stored on pages in tempdb. However I didn't address whether there was any difference in behaviour when it comes to writing these pages to persistent storage.
I've done a small amount of testing on this now and so far have seen no such difference. In the specific test I did on my instance of SQL Server 250 pages seems to be the cut off point before the data file gets written to.
NB: The behavior below no longer occurs in SQL Server 2014 or SQL Server 2012 SP1/CU10 or SP2/CU1 the eager writer is no longer as eager to flush pages. More details on that change at SQL Server 2014: tempdb Hidden Performance Gem.
Running the below script
CREATE TABLE #T(X INT, Filler char(8000) NULL)
INSERT INTO #T(X)
SELECT TOP 250 ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master..spt_values
DROP TABLE #T
Monitoring writes to the tempdb data file with Process Monitor, I saw none (except occasionally ones to the database boot page at offset 73,728). After changing 250 to 251 I began to see writes as below.

The screenshot above shows 5 * 32 page writes and one single page write indicating that 161 of the pages were written. I got the same cut off point of 250 pages when testing with table variables too. The script below shows it a different way by looking at sys.dm_os_buffer_descriptors
DECLARE @T TABLE (
X INT,
[dba.se] CHAR(8000) NULL)
INSERT INTO @T
(X)
SELECT TOP 251 Row_number() OVER (ORDER BY (SELECT 0))
FROM master..spt_values
SELECT is_modified,
Count(*) AS page_count
FROM sys.dm_os_buffer_descriptors
WHERE database_id = 2
AND allocation_unit_id = (SELECT a.allocation_unit_id
FROM tempdb.sys.partitions AS p
INNER JOIN tempdb.sys.system_internals_allocation_units AS a
ON p.hobt_id = a.container_id
INNER JOIN tempdb.sys.columns AS c
ON c.object_id = p.object_id
WHERE c.name = 'dba.se')
GROUP BY is_modified
| is_modified | page_count |
|---|---|
| 0 | 192 |
| 1 | 61 |
Showing that 192 pages were written and the dirty flag cleared. It also shows that being written doesn't mean that pages will be evicted from the buffer pool immediately. The queries against this table variable could still be satisfied entirely from memory.
On an idle server with max server memory set to 2000 MB and DBCC MEMORYSTATUS reporting Buffer Pool Pages Allocated as approx 1,843,000 KB (c. 23,000 pages) I inserted to the tables above in batches of 1,000 rows/pages and for each iteration recorded.
SELECT Count(*)
FROM sys.dm_os_buffer_descriptors
WHERE database_id = 2
AND allocation_unit_id = @allocId
AND page_type = 'DATA_PAGE'
Both the table variable and the #temp table gave nearly identical graphs and managed to pretty much max out the buffer pool before getting to the point that they weren't entirely held in memory so there doesn't seem to be any particular limitation on how much memory either can consume.
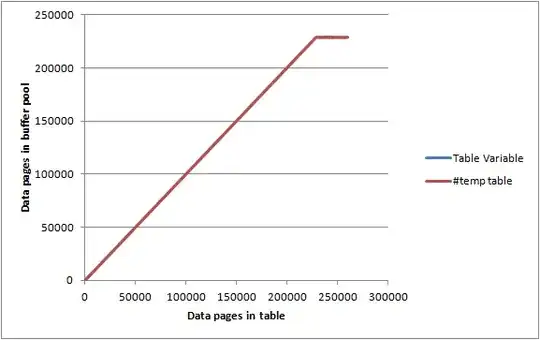
There are a few things I'd like to point out based more on particular experiences rather than study. As a DBA, I'm very new so please do correct me where required.